
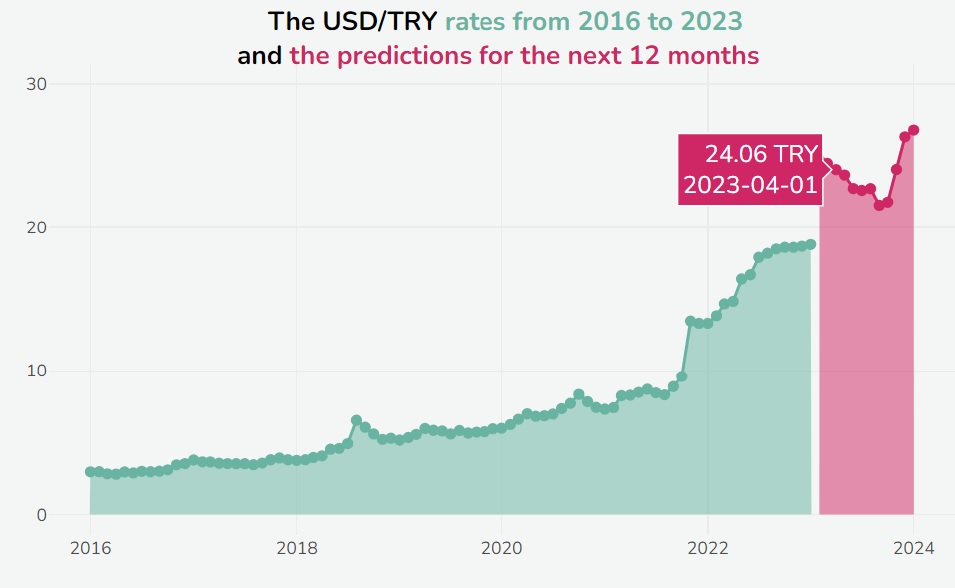
The ongoing debate recently in Turkey is that the Turkish government has suppressed US Dollar/Turkish Lira exchange rates (USD/TRY) to prevent economic turmoil. Many authorities in the business, especially exporters, think that the USD/TRY parity should be in the range of 24-25 Turkish Lira.
To look through that, we will predict for the whole year and see whether the rates are in rational intervals. But first, we will model our data with bagged multivariate adaptive regression splines (MARS) via the earth package. The predictors of our regression model are the current account (account) and the producer price index (ppi) of Turkey.
library(tidyverse)
library(tidymodels)
library(lubridate)
library(timetk)
library(tsibble)
library(modeltime)
library(baguette)
library(fable)
library(plotly)
library(ggtext)
library(systemfonts)
library(showtext)
df <- read_csv("https://raw.githubusercontent.com/mesdi/blog/main/usdtry_mars.csv")
#Turkiye Current Account (USD)
df_ca <-
df %>%
filter(type == "ca") %>%
mutate(date =
#removing parentheses and text within
case_when(str_detect(date," \\(.*\\)") ~ str_remove(date," \\(.*\\)"),
TRUE ~ date)) %>%
mutate(
date = parse_date(date, format = "%b %d, %Y") %>%
#subtracting 2 months from release date
floor_date("month") %m-% months(2),
value = str_remove(value, "B") %>% as.numeric()
) %>%
select(date, account = value)
#Turkiye Producer Price Index (TRY)
df_ppi <-
df %>%
filter(type == "ppi") %>%
mutate(date =
#removing parentheses and text within
case_when(str_detect(date," \\(.*\\)") ~ str_remove(date," \\(.*\\)"),
TRUE ~ date)) %>%
mutate(
date = parse_date(date, format = "%b %d, %Y") %>%
#subtracting 1 months from release date
floor_date("month") %m-% months(1),
value = str_remove(value, "B") %>% as.numeric()
) %>%
select(date, ppi = value)
#USD/TRY - US Dollar Turkish Lira
df_usdtry <-
df %>%
filter(type == "usdtry") %>%
mutate(
date = parse_date(date, format = "%m/%d/%Y"),
value = as.numeric(value)
) %>%
select(date, usdtry = value)
#Merging all the datasets
df_tidy <-
df_usdtry %>%
left_join(df_ppi, by = "date") %>%
left_join(df_ca, by = "date") %>%
na.omit()
Now that we have created our dataset, we can start modeling. Because the variables are in different scales, we normalize all of them. And we have to convert the categorical variables to numeric ones due to package/engine necessity.
#Splitting the data for train and test data
splits <-
df_tidy %>%
time_series_split(assess = "1 year",
cumulative = TRUE,
date_var = date)
df_train <- training(splits)
df_test <- testing(splits)
#Add time series signature
df_rec_ts <-
recipe(usdtry ~ ., data = df_train) %>%
step_timeseries_signature(date)
#Preprocessing
df_rec_tidy <-
df_rec_ts %>%
step_rm(date) %>%
step_rm(contains("iso"),
contains("minute"),
contains("hour"),
contains("am.pm"),
contains("xts")) %>%
step_zv(all_numeric_predictors()) %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(contains("lbl"), one_hot = TRUE)
We do hyperparameter tuning in order to find the optimal model for the data. As seen below, the degree of interaction is 2, which means there is an interaction term, and it exercises the backward pruning method.
#Processed data for determining the number of model terms
df_proc <-
df_rec_tidy %>%
prep() %>%
bake(new_data = NULL)
#Model specification
mars_spec <-
bag_mars(num_terms = min(200, max(20, 2 * ncol(df_proc))) + 1,
prod_degree = tune(),#marks for tuning
prune_method = tune()) %>%
set_engine("earth") %>%
set_mode("regression")
#Workflow
mars_wflow <-
workflow() %>%
add_model(mars_spec) %>%
add_recipe(df_rec_tidy)
#cross-validation for resamples
set.seed(12345)
df_folds <- vfold_cv(df_train)
#Building the hyperparameter data frame for tuning
hyper_grid <- crossing(
prod_degree = 1:2,
prune_method = c("backward", "forward")
)
#Hyperparameter Tuning
mars_reg_tune <-
mars_wflow %>%
tune_grid(
df_folds,
grid = hyper_grid,
metrics = metric_set(rsq)
)
#Selecting the best parameters according to the r-square
mars_param_best <-
select_best(mars_reg_tune, metric = "rsq") %>%
select(-.config)
mars_param_best
# A tibble: 1 x 2
# prod_degree prune_method
# <int> <chr>
#1 2 backward
We can build our model with the best parameters we found earlier tuning process.
#Final workflow with the object of best parameters
final_df_wflow <-
workflow() %>%
add_model(mars_spec) %>%
add_recipe(df_rec_tidy) %>%
finalize_workflow(mars_param_best)
#Model table
set.seed(2023)
model_table <- modeltime_table(
final_df_wflow %>%
fit(df_train)
)
#Calibration
calibration_table <-
model_table %>%
modeltime_calibrate(df_test)
#Accuracy
calibration_table %>%
modeltime_accuracy() %>%
select(rmse, rsq)
# A tibble: 1 x 2
# rmse rsq
# <dbl> <dbl>
#1 2.55 0.543
When we look at the accuracy results coefficient of determination (rsq) looks low because the accuracy measures are calculated based on test data in the calibration phase, and our test data’s time range is small. But the RMSE looks fine, considering the target variable.
Before we start the modeling, we create our future data set to use in the regression model as a predictor. We will use the automated ARIMA function to do that. When we analyze the ARIMA models for ppi and account variables, we could see that they have an annual seasonality.
#Future dataset for the next 12 months
date <-
df_tidy %>%
mutate(date = yearmonth(date)) %>%
as_tsibble() %>%
new_data(12) %>%
as_tibble() %>%
mutate(date = as.Date(date))
ppi <-
df_tidy %>%
mutate(date = yearmonth(date)) %>%
as_tsibble() %>%
model(ARIMA(ppi)) %>%
forecast(h = 12) %>%
as_tibble() %>%
select(ppi = .mean)
account <-
df_tidy %>%
mutate(date = yearmonth(date)) %>%
as_tsibble() %>%
model(ARIMA(account)) %>%
forecast(h = 12) %>%
as_tibble() %>%
select(account = .mean)
df_future <-
date %>%
bind_cols(ppi) %>%
bind_cols(account)
Finally, we can plot the actual values from 2016 to 2023 and predictions for the next 12 months.
#Forecasting plot dataset
set.seed(1983)
df_plot <-
calibration_table %>%
modeltime_refit(df_tidy) %>%
modeltime_forecast(
new_data = df_future,
actual_data = df_tidy %>% filter(year(date) > 2015)
)
#The observation dataset
df_actual <-
df_plot %>%
filter(.key == 'actual')
#The prediction dataset
df_pred <-
df_plot %>%
filter(.key == 'prediction')
#importing google fonts
font_add_google("Nunito", "nuni" )
showtext_auto()
#Hoverinfo texts
text_actual <- glue::glue("{round(df_actual$.value, 2)} TRY\n{df_actual$.index}")
text_pred <- glue::glue("{round(df_pred$.value, 2)} TRY\n{df_pred$.index}")
df_plot %>%
ggplot(aes(.index, .value)) +
geom_area(
data = . %>% filter(.key == "actual"),
fill="#69b3a2",
alpha=0.5
) +
geom_line(
data = . %>% filter(.key == "actual"),
color ="#69b3a2"
) +
geom_point(aes(text = text_actual),
data = . %>% filter(.key == "actual"),
color ="#69b3a2"
) +
geom_area(
data = . %>% filter(.key == "prediction"),
fill="#cf2765",
alpha=0.5
) +
geom_line(
data = . %>% filter(.key == "prediction"),
color = "#cf2765"
) +
geom_point(aes(text = text_pred),
data = . %>% filter(.key == "prediction"),
color = "#cf2765"
) +
scale_y_continuous(limits = c(0,30))+
labs(
x = "",
y = "",
title = "The USD/TRY <span style = 'color:#69b3a2'>rates from 2016 to 2023</span>\nand <span style = 'color:#cf2765'>the predictions for the next 12 months</span>"
) +
theme_minimal()+
theme(
plot.title =
element_markdown(
hjust = 0.5,
face = "bold"
),
plot.background = element_rect(fill = "#f3f6f4", color = NA),
panel.background = element_rect(fill = "#f3f6f4", color = NA)
) -> p
#setting font family for ggplotly
font <- list(
family= "Nunito",
size=20
)
#setting font family for hover label
label <- list(
font = list(
family = "Nunito",
size = 16
)
)
#converts ggplot2 object to plotly for interactive chart
ggplotly(p, tooltip = "text") %>%
style(hoverlabel = label) %>%
layout(font = font) %>%
#Remove plotly buttons from the mode bar
config(displayModeBar = FALSE)

When we hover over the points, we can see that the April data is quite similar to the expectations of the Turkish exporters and, the majority of economists. So, in the near future, the parity might explode, especially after the election is to be held on May 14.


Leave a comment