

While the US midterm election escalated, the dollar’s performance weakened; especially this situation happened against the Asian currencies. South Korean won(KRW) is the best performer among them. The Chinese yuan(CNY) was behind its counterparts because of their aggressive public health measures related to the zero-COVID protocol.
Let’s add the Japanese yen(JPY) and Malaysian ringgit(MYR) to the above currencies and analyze them via the timetk package. First, we will compare the mentioned Asian FX rates between 2018-2022 years with line charts.
library(tidymodels)
library(modeltime)
library(tidyverse)
library(timetk)
library(plotly)
library(tidyquant)
library(glue)
df <-
read_csv("https://raw.githubusercontent.com/mesdi/blog/main/fx.csv") %>%
mutate(date = parse_date(date, "%m/%d/%Y"))
#Comparing with the daily line plots
df %>%
group_by(symbol) %>% #for facetting
plot_time_series(date,
value,
.facet_ncol = 2,
.interactive = FALSE,
.title = "") +
theme(strip.background = element_rect(fill="#215a4d", color ="#215a4d"))
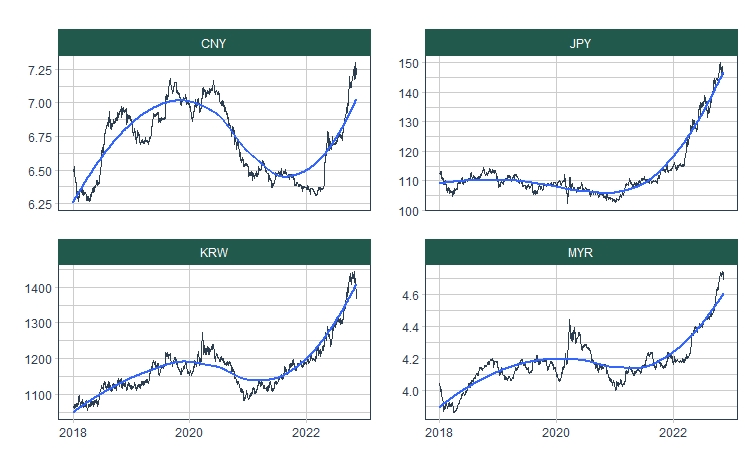
The things we talked about seem to fit the above charts. Now, we adjust our data from daily to hourly frequency to see the detailed pattern of the last month. We will pad the data with linear extrapolation.
#Low to high frequency
df %>%
group_by(symbol) %>%
pad_by_time(date, .by = "hour") %>%
mutate(across(value, .fns = ts_impute_vec, period = 1)) %>%
filter_by_time(date, "2022-10", LAST(date)) %>%
plot_time_series(date,
value,
.facet_ncol = 2,
.interactive = FALSE,
.line_size = 1,
.title = "") +
theme(strip.background = element_rect(fill="#9da832", color ="#9da832"))

Most of them seem to have decline trend according to the charts above. To examine this trend, we will model one of them, the Chinese yuan. And we will forecast for the next 3 months via the modeltime package.
#Building train and test set
df_split <-
df %>%
filter(symbol == "CNY") %>%
time_series_split(assess = "2 months", cumulative = TRUE)
df_train <- training(df_split)
df_test <- testing(df_split)
#Preprocessing
df_rec <-
recipe(value ~ date, data = df_train) %>%
step_timeseries_signature(date) %>% #adding time series signatures
step_fourier(date, period = 365, K = 5) %>%
step_rm(date) %>%
step_rm(contains("iso"),
contains("minute"),
contains("hour"),
contains("am.pm"),
contains("xts")) %>%
step_normalize(contains("index.num"), date_year) %>%
step_dummy(contains("lbl"), one_hot = TRUE)
#Modeling (with random forest) and fitting
df_spec <-
rand_forest(trees = 1000) %>%
set_engine("ranger") %>%
set_mode("regression")
workflow_df <-
workflow() %>%
add_recipe(df_rec) %>%
add_model(df_spec)
set.seed(12345)
workflow_df_fit <-
workflow_df %>%
fit(data = df_train)
#Model and calibration table
model_table <- modeltime_table(workflow_df_fit)
df_calibration <-
model_table %>%
modeltime_calibrate(df_test)
#Accuracy
df_calibration %>%
modeltime_accuracy() %>%
select(rsq)
# A tibble: 1 x 1
# rsq
# <dbl>
#1 0.654
According to the accuracy results, we can say that our model can explain the %65 of the change in rates, which is not bad. Now, we can forecast with that model.
#Forecasting the next 3 months
df_calibration %>%
modeltime_refit(df %>% filter(symbol == "CNY")) %>%
modeltime_forecast(h = "3 months", #forecast horizon
actual_data = df %>% filter(symbol == "CNY")) %>%
plot_modeltime_forecast(.interactive = TRUE,
.legend_show = FALSE,
.title = "Forecast Plot of CNY Rates for the Next 3 Months") %>%
#customizing the hoverinfo texts of the traces(lines)
style(text = glue("{.$x$data[[1]]$x}\n{.$x$data[[1]]$y}"), traces = 1) %>%
style(text = glue("{.$x$data[[2]]$x}\n{round(.$x$data[[2]]$y, 4)}"), traces = 2) %>%
style(text = glue("{.$x$data[[3]]$x}\n{round(.$x$data[[3]]$y, 4)}"), traces = 3) %>%
style(text = glue("{.$x$data[[4]]$x}\n{round(.$x$data[[4]]$y, 4)}"), traces = 4)
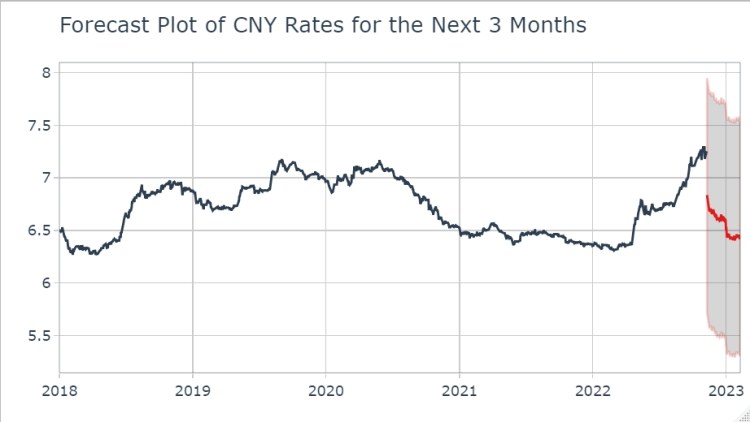
The forecasting plot confirms the declining trend of the high-frequency CNY rates.


Leave a comment