
Recently, I read a tweet that reports children who grow up in poor conditions earn much less as adults than those with better conditions. I believe one of the best ways to check that is to compare childhood education participation rates with wealth in related countries; to do that, I will use early childhood education enrollment and household net worth rates from OECD.
Now, we will draw the childhood education rates by age as a stacked barplot and add the household net worth rates of the best 20 countries as a second y-axis line.
library(tidyverse)
library(tidymodels)
library(countrycode)
library(plotly)
library(sysfonts)
library(showtext)
library(glue)
library(scales)
library(janitor)
library(DALEXtra)
library(bbplot)
#Loading the datasets
df_childhood <- read_csv("https://raw.githubusercontent.com/mesdi/blog/main/childhood.csv")
df_household <- read_csv("https://raw.githubusercontent.com/mesdi/blog/main/household.csv")
#Joining them by country and time
df <-
df_childhood %>%
left_join(df_household, by = c("country", "time")) %>%
na.omit()
#Wrangling the dataset
df_tidy <-
df %>%
mutate(household = round(household, 2),
childhood = round(childhood, 2),
age = str_replace(age, "_", "-"),
country_name = countrycode(country, "genc3c", "country.name")
)
#Best 20 countries based on the household net worth in their last year
df_tidy %>%
group_by(country) %>%
slice_max(time) %>%
slice_max(household, n=20) %>%
mutate(age = fct_reorder(age, childhood, .desc = TRUE),
country_name = fct_reorder(country_name, household, .desc = TRUE)) %>%
ggplot(aes(x=country_name,
y=childhood,
fill = age,
#Hover text of the barplot
text = glue("{country}\n%{childhood}\n{age}\nChildhood education"))) +
geom_col() +
geom_line(aes(y=household/2, group = 1),
color= "skyblue",
size=1) +
#Adding the household net worth as a second(dual) y-axis
scale_y_continuous(sec.axis = sec_axis(~.*2)) +
scale_fill_viridis_d(name = "") +
xlab("") +
ylab("") +
theme_minimal() +
theme(
axis.text.x = element_text(angle = 60),
axis.text.y = element_blank(),
axis.text.y.right = element_blank(),
panel.grid = element_blank(),
legend.position = "none"
) -> p
#adding google font
font_add_google(name = "Henny Penny", family = "henny")
showtext_auto()
#setting font family for ggplotly
font <- list(
family= "Henny Penny",
size =5
)
#Plotly chart
ggplotly(p, tooltip = c("text")) %>%
#Hover text of the line
style(text = glue("{unique(p$data$country)}\n%{unique(p$data$household)}\nHousehold net worth"),traces = 6) %>%
layout(font=font)
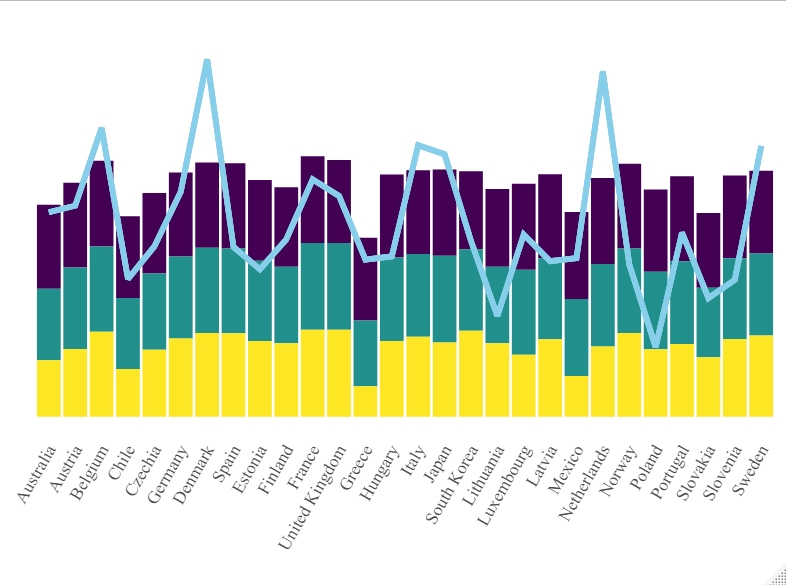
We will examine how the particular age group of students affects household net worth; to do that, we convert age levels to variables for modeling.
#Splitting the data into train and test sets
set.seed(1234)
df_split <-
df_tidy %>%
#Converting the levels to variables for modeling
pivot_wider(names_from = age, values_from = childhood) %>%
clean_names() %>%
na.omit() %>%
initial_split()
df_train <- training(df_split)
df_test <- testing(df_split)
We will use Bayesian additive regression trees(BART) which can be considered the sum of trees ensemble model.
#Preprocessing
df_rec <- recipe(household ~ age_3 + age_4 + age_5, data = df_train)
#Modeling with BART
df_spec <-
parsnip::bart() %>%
set_engine("dbarts") %>%
set_mode("regression")
#Workflow
df_wf <-
workflow() %>%
add_recipe(df_rec) %>%
add_model(df_spec)
#cross-validation for resamples
set.seed(12345)
df_folds <- vfold_cv(df_train)
#Resampling for the accuracy metrics
set.seed(98765)
df_rs <-
df_wf %>%
fit_resamples(resamples = df_folds)
#Computes the accuracy metrics
collect_metrics(df_rs)
# A tibble: 2 x 6
# .metric .estimator mean n std_err .config
# <chr> <chr> <dbl> <int> <dbl> <chr>
#1 rmse standard 85.2 10 4.79 Preprocessor1_Model1
#2 rsq standard 0.528 10 0.0458 Preprocessor1_Model1
As seen from the above rsq result, we need to tune the model to improve the goodness of fit via Grid Search.
#Model tuning with grid search
df_spec <-
parsnip::bart(
trees = tune(),
prior_terminal_node_coef = tune(),
prior_terminal_node_expo = tune()
) %>%
set_engine("dbarts") %>%
set_mode("regression")
#parameter object
rf_param <-
workflow() %>%
add_model(df_spec) %>%
add_recipe(df_rec) %>%
extract_parameter_set_dials() %>%
finalize(df_train)
#space-filling design with integer grid argument
df_reg_tune <-
workflow() %>%
add_recipe(df_rec) %>%
add_model(df_spec) %>%
tune_grid(
df_folds,
grid = 20,
param_info = rf_param,
metrics = metric_set(rsq)
)
#Selecting the best parameters according to the r-square
rf_param_best <-
select_best(df_reg_tune, metric = "rsq") %>%
select(-.config)
#Final estimation with the object of best parameters
final_df_wflow <-
workflow() %>%
add_model(df_spec) %>%
add_recipe(df_rec) %>%
finalize_workflow(rf_param_best)
set.seed(12345)
final_df_fit <-
final_df_wflow %>%
last_fit(df_split)
#Computes final the accuracy metrics
collect_metrics(final_df_fit)
# A tibble: 2 x 4
# .metric .estimator .estimate .config
# <chr> <chr> <dbl> <chr>
#1 rmse standard 84.5 Preprocessor1_Model1
#2 rsq standard 0.645 Preprocessor1_Model1
There seems to be a significantly better improvement. Now, we can move on to measure the variable importance with our newly tuned parameters.
#Creating a preprocessed dataframe of the train dataset
imp_data <-
df_rec %>%
prep() %>%
bake(new_data = NULL)
#Final modeling with the best parameters
df_spec_final <-
parsnip::bart(
trees = 80,
prior_terminal_node_coef = 0.884,
prior_terminal_node_expo = 0.713
) %>%
set_engine("dbarts") %>%
set_mode("regression")
#building the explainer-object
explainer_df <-
explain_tidymodels(
df_spec_final %>%
fit(household ~ ., data = imp_data),
data = imp_data %>% select(-household),
y = df_train$household,
verbose = FALSE
)
set.seed(1983)
#calculates the variable-importance measure
vip_df <-
model_parts(
explainer = explainer_df,
loss_function = loss_root_mean_square,
B = 100, #the number of permutations
type = "difference",
label =""
)
#Plotting ranking of the importance of explanatory variables
plot(vip_df) +
ggtitle("Mean variable-importance over 100 permutations", "")+
theme(plot.title = element_text(hjust = 0.5, size = 20),
axis.title.x = element_text(size=15),
axis.text = element_text(size=15))
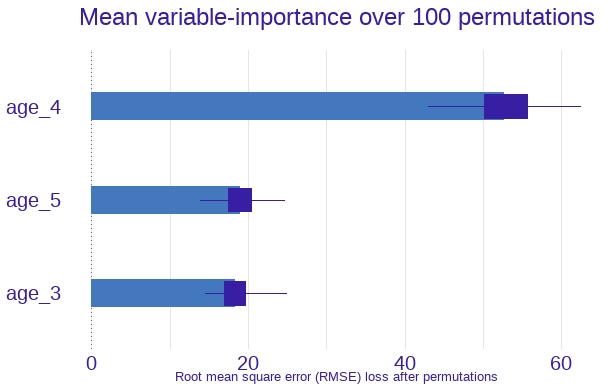
It is clearly seen that the 4-year old students have far the most effect on the household net worth rates according to the above graph. Now, we are going to see how the household net worth rates change to the enrolment rate of 4-year-old students via the partial dependence profiles method.
#Partial dependence profiles for 4-years old students
set.seed(2403)
pdp_age <- model_profile(explainer_df, variables = "age_4")
as_tibble(pdp_age$agr_profiles) %>%
ggplot(aes(`_x_`, `_yhat_`)) +
geom_line(data = as_tibble(pdp_age$cp_profiles),
aes(x = age_4, group = `_ids_`),
size = 0.5, alpha = 0.05, color = "gray50")+
geom_line(color = "midnightblue", size = 1.2, alpha = 0.8)+
bbc_style()+
labs(title= "Household vs. AGE-4")+
theme(plot.title = element_text(hjust = 0.5),
panel.grid.minor.x = element_line(color="grey"))

According to the above plot, as 4-year-olds’ enrollment rates have increased, household net worth ratios rise; especially after 80%, the trend increases exponentially. So, we can say that the education enrollment rate of 4-year-old children significantly and positively affects being wealthy.


Leave a comment