
In the last article, we analyzed carbon emissions and the effects that created them. This time I want to look into another important environmental issue, animal biodiversity; by animals, I mean mammals, birds, fish, reptiles, and amphibians.
The metric we are going to be interested in is the living planet index which measures the change in the number of 31,831 populations across 5,230 species relative to the year 1970. The explanatory variables we will take, are annual carbon emissions per capita(co2), annual gross domestic product per capita(gdp), and regions(region).
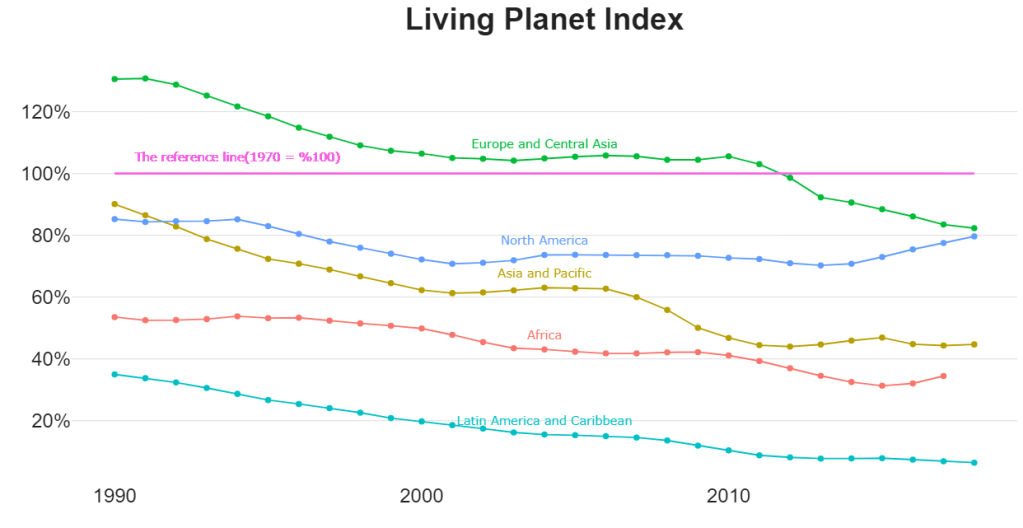
First, we will compare the living planet index(lpi) by region. To do that, we will create our datasets; because we do that by regions, we will summarize the co2 and gdp variables by the relative region.
library(tidyverse)
library(tidymodels)
library(DALEX)
library(DALEXtra)
library(janitor)
library(plotly)
library(bbplot)
library(scales)
library(countrycode)
library(glue)
df_co <- read_csv("https://raw.githubusercontent.com/mesdi/blog/main/co-emissions-per-capita.csv")
df_gdp <- read_csv("https://raw.githubusercontent.com/mesdi/blog/main/gdp-per-capita-worldbank.csv")
df_lpi <- read_csv("https://raw.githubusercontent.com/mesdi/blog/main/global-living-planet-index.csv")
#Building the main dataset
df_co_gdp <-
df_gdp %>%
left_join(df_co) %>%
clean_names() %>%
#continent names
mutate(region = countrycode(sourcevar = entity,
origin = "country.name",
destination = "region")) %>%
select(
year,
region,
co2= annual_co2_emissions_per_capita,
gdp= gdp_per_capita_ppp_constant_2017_international) %>%
na.omit() %>%
#adjusting the region values for merging with the LPI data frame
mutate(
region = str_replace(region, "&", "and"),
region=case_when(
region=="South Asia" | region == "East Asia and Pacific" ~ "Asia and Pacific",
region=="Middle East and North Africa" | region == "Sub-Saharan Africa" ~ "Africa",
TRUE ~ region
)) %>%
#summing the co2 and gdp values by the region, separately
group_by(region,year) %>%
summarise(co2= sum(co2),
gdp= sum(gdp))
df_tidy <-
df_lpi %>%
left_join(df_co_gdp) %>%
na.omit()
#Comparing the regions by plotting
p <-
df_tidy %>%
ggplot(aes(x= year,
y=lpi,
color=region,
group=region,
#text variable for hoverinfo
text = glue("{number(round(lpi), suffix='%')}\n{year}")))+
geom_line()+
#the reference line
geom_line(aes(y=100,color="red"))+
geom_point()+
#region texts
geom_text(data = df_tidy %>%
group_by(region) %>%
filter(year==round(median(year))),
aes(x= year, y= lpi,label=region),
show.legend = FALSE,
nudge_y = 4.2
)+
#the reference line text
geom_text(aes(x = 1994,
y=105, color= "red",
label = "The reference line(1970 = %100)"))+
scale_y_continuous(breaks = pretty_breaks(),
labels = label_percent(scale = 1))+
labs(title = "Living Planet Index")+
bbc_style() +
theme(legend.position = "none", #removes the legend keys
plot.title = element_text(hjust = 0.5))
#plotly for interactive plotting
ggplotly(p, tooltip = c("text")) %>%
#removes the reference line info
style(hoverinfo = "none",traces = 6)
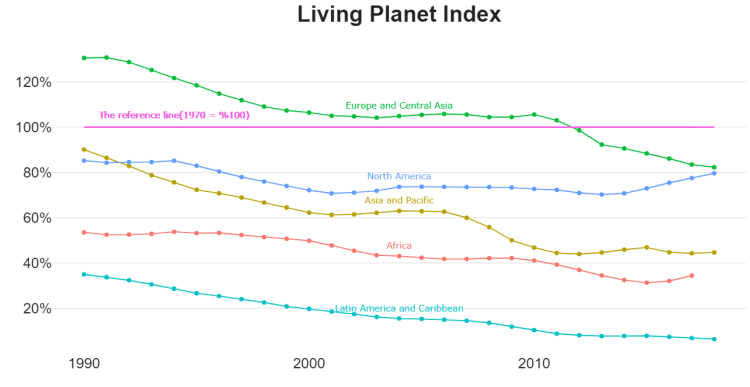
When we look at the regions, it seems they are all under their 1970-year values. We will now examine the underlying reasons for this. To do that, we will first model the data with a support vector machine with kernel-based algorithms.
#Splitting our data into train and test sets
set.seed(1234)
df_split <- initial_split(df_tidy %>% select(-year))
df_train <- training(df_split)
df_test <- testing(df_split)
#Preprocessing the data
df_rec <-
recipe(lpi ~ ., data = df_train) %>%
step_dummy(all_nominal_predictors(), one_hot = TRUE) %>%
#all numeric predictors should be in the same unit
step_normalize(all_numeric_predictors())
#Modeling with svm with kernel-based algorithms
df_spec <-
svm_linear() %>%
set_engine("kernlab") %>%
set_mode("regression")
df_wf <-
workflow() %>%
add_recipe(df_rec) %>%
add_model(df_spec)
#cross-validation for resamples
set.seed(12345)
df_folds <- vfold_cv(df_train, strata = region)
#Resampling for the accuracy metrics
set.seed(234)
df_rs <-
df_wf %>%
fit_resamples(resamples = df_folds)
#computes the accuracy metrics
collect_metrics(df_rs)
# A tibble: 2 x 6
# .metric .estimator mean n std_err .config
# <chr> <chr> <dbl> <int> <dbl> <chr>
#1 rmse standard 4.32 10 0.387 Preprocessor1~
#2 rsq standard 0.980 10 0.00528 Preprocessor1~
#fits the best model to the training set
#and evaluate it with the testing set.
final_fit <- last_fit(df_wf, df_split)
collect_metrics(final_fit)
# A tibble: 2 x 4
# .metric .estimator .estimate .config
# <chr> <chr> <dbl> <chr>
#1 rmse standard 7.27 Preprocessor1_Model1
#2 rsq standard 0.963 Preprocessor1_Model1
The above accuracy results look fine to step forward with that model. Now, we can compute and draw permutation-based variable importance scores.
#Permutation-based variable importance
#Creating a preprocessed dataframe of the train dataset
imp_data <-
df_rec %>%
prep() %>%
bake(new_data = NULL)
#building the explainer-object
explainer_svm <-
explain_tidymodels(
df_spec %>%
fit(lpi ~ ., data = imp_data),
data = imp_data %>% select(-lpi),
y = df_train$lpi,
verbose = FALSE
)
set.seed(1983)
#calculates the variable-importance measure
vip_svm <-
model_parts(
explainer = explainer_svm,
loss_function = loss_root_mean_square,
B = 100, #the number of permutations
type = "difference",
label =""
)
#Plotting ranking of the importance of explanatory variables
plot(vip_svm) +
ggtitle("Mean variable-importance over 100 permutations", "")+
theme(plot.title = element_text(hjust = 0.5))
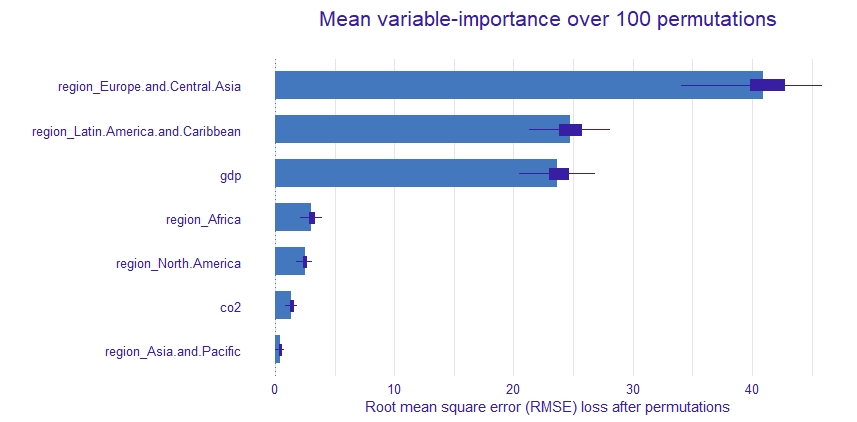
The interesting thing we can extract from the above plot is that the carbon emission variable(co2) is a very weak effect on the LPI index. Instead of it, Europe and Latin America regions, and the gdp variables look to have far the most dominant effects on the index.


Leave a comment