
The side effect of the ongoing Russian occupation was that it stimulated countries’ intentions to increase their military budgets. Last month following the invasion, Germany announced a budget of 100 billion € for the restructuring of the army and announced that it would spend %2 of its GDP every year.
Of course, it is not a good development for the world. For this reason, I’ve just wondered which motives affect the military spending of the countries. I will take G20 countries’ annual military expenditure as a target variable. And as the predictors:
All the data we will use is from Our World in Data. We are going to use a linear model with simulations in which the Markov chain Monte Carlo(MCMC) method generates samples from Bayesian posterior distributions. This process is called JAGS and in order to use that, we will use rjags package. But we have to install JAGS library separately.
First, we create a data frame that we are going to use in analysis and modeling.
library(tidyverse)
library(readxl)
library(sysfonts)
library(showtext)
library(rjags)
library(coda)
df <- read_excel("military_expenditure.xlsx")
#Creating region variable for comparing analysis and
#region_int variable for jags modeling
df <-
df %>%
mutate(region=if_else(country %in% c("Australia","China","India","Indonesia",
"Japan","Russia","Saudi Arabia",
"South Africa","South Korea","Turkey"),
"East","West") %>% as_factor(),
region_int = region %>% as.integer()) %>%
na.omit() %>%
as.data.frame()
We will examine the expenditure of the G20 countries from the cold war ends until the recent, for comparison. We colorize each region separately.
#load fonts(google)
font_add_google("Roboto Slab")
showtext_auto()
#Comparison Plot
df %>%
filter(year > 1991) %>%
mutate(country = fct_reorder(country, expenditure)) %>%
ggplot(aes(expenditure, country, fill = region, color = region)) +
geom_boxplot(position = position_dodge(), alpha = 0.5) +
scale_x_log10(labels = scales::label_number_si()) +
scale_fill_brewer(palette = "Pastel1") +
scale_color_brewer(palette = "Pastel1") +
labs(y = NULL, color = NULL, fill = NULL, x = "Military Expenditures per Country($)")+
theme_minimal()+
theme(legend.position = "right",
panel.background = element_rect(fill = "#e5f5f9",color = NA),
axis.text = element_text(family = "Roboto Slab", size = 10),
axis.title = element_text(family = "Roboto Slab"))
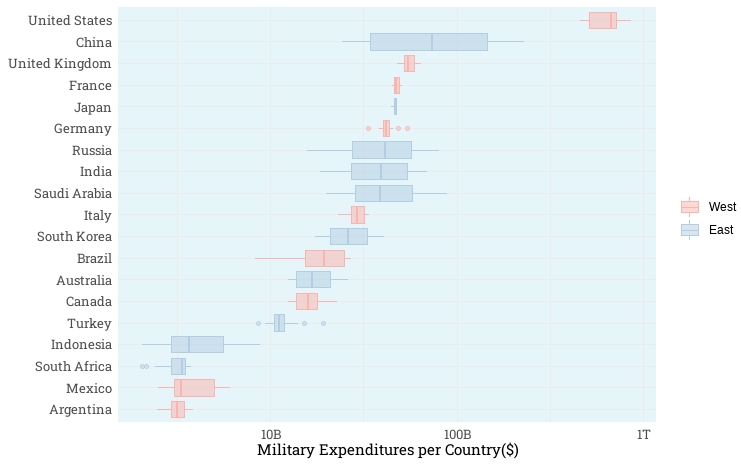
The interesting thing is Germany doesn’t appear so much different from Russia.
First of all, we will build the model with the region variable we created before, so we will see its effect on military expenditures change. Because of the jags.model function can not employ non-numeric data as predictors we have to use the integer type of region variable (region_int) we created before.
#modeling with region
set.seed(123)
model_with <-
lm(expenditure ~ civlib + gdp + region, data = df)
> model_with
#Call:
#lm(formula = expenditure ~ civlib + gdp + region, data = df)
#Coefficients:
#(Intercept) civlib gdp regionEast
# -3.052e+10 7.380e+10 5.367e-02 -4.726e+10
Because of the linear model above, we take the region variable as regionEast from now.
#the dataset for jags model
lt_with <- list(x = df[,c(3, 4, 7)], y = df[,5],
n = nrow(df))
#estimation coefficients
lt_with$b_guess <- model_with$coefficients
#Model string
jags.script_with <-
"#--------------------------------------------------
model{
# likelihood
for( i in 1:n) {
y[i] ~ dnorm(mu[i], tau)
mu[i] <- intercept + civlib*x[i,1] + gdp*x[i,2]+ regionEast*x[i,3]
}
# priors
intercept ~ dnorm(b_guess[1], 0.1)
civlib ~ dnorm(b_guess[2], 0.1)
gdp ~ dnorm(b_guess[3], 0.1)
regionEast ~ dnorm(b_guess[4], 0.1)
tau ~ dgamma(.01,.01)
# transform
sigma <- 1 / sqrt(tau)
}#--------------------------------------------------
"
#compiling
mod_with <- jags.model(textConnection(jags.script_with),
data = lt_with,
n.chains = 4, n.adapt = 2000)
#burn-in process
update(mod_with, 1000)
#posterior sampling
mod.samples_with <- coda.samples(
model = mod_with,
variable.names = c("intercept", "civlib", "gdp", "regionEast", "sigma"),
n.iter = 1000)
# descriptive statistics of posteriors
sm_with <- summary(mod.samples_with)
sm_with[1]
#$statistics
# Mean SD Naive SE Time-series SE
#civlib 7.379818e+10 3.127715e+00 4.945351e-02 4.885913e-02
#gdp 7.665518e-02 2.448805e-03 3.871901e-05 3.598913e-05
#intercept -3.051892e+10 3.197261e+00 5.055314e-02 5.056658e-02
#regionEast -4.726244e+10 3.099717e+00 4.901083e-02 4.900839e-02
#sigma 1.182377e+11 2.493767e+09 3.942992e+07 3.798331e+07
As you can see above, the GDP variable has no effect, while the eastern region(regionEast) is a powerful predictor. This time we will exclude the region variable and compare the variables’ effect for each state on a plot. To fully understand the process and parameters, I’d recommend reading the JAGS User Manual Chapter 3. We will prefer time series SE as the standard error for calculating the prediction intervals because it takes into account auto-correlation.
#without region
model_without <-
lm(expenditure ~ civlib + gdp, data = df)
#the dataset for jags model
lt_without <- list(x = df[,c(3, 4)], y = df[,5],
n = nrow(df))
#estimation coefficients
lt_without$b_guess <- model_without$coefficients
# Model string
jags.script_without <-
"#--------------------------------------------------
model{
# likelihood
for( i in 1:n) {
y[i] ~ dnorm(mu[i], tau)
mu[i] <- intercept + civlib*x[i,1] + gdp*x[i,2]
}
# priors
intercept ~ dnorm(b_guess[1], 0.1)
civlib ~ dnorm(b_guess[2], 0.1)
gdp ~ dnorm(b_guess[3], 0.1)
tau ~ dgamma(.01,.01)
# transform
sigma <- 1 / sqrt(tau)
}#--------------------------------------------------
"
#compiling
mod_without <- jags.model(textConnection(jags.script_without),
data = lt_without,
n.chains = 4, n.adapt = 2000)
#burn-in process
update(mod_with, 1000)
#posterior sampling
mod.samples_without <- coda.samples(
model = mod_without,
variable.names = c("intercept", "civlib", "gdp", "sigma"),
n.iter = 1000)
# descriptive statistics of posteriors
sm_without <- summary(mod.samples_without)
#The plot of the effects of the terms on the change of expenditure
bind_rows(
sm_with$statistics %>%
as_tibble(rownames = "terms") %>%
rename("mean"= Mean,
"std.error" = `Time-series SE`) %>%
select(c(1,2,5)) %>%
mutate(regions = "include"),
sm_without$statistics %>%
as_tibble(rownames = "terms") %>%
rename("mean"= Mean,
"std.error" = `Time-series SE`) %>%
select(c(1,2,5)) %>%
mutate(regions = "not include")
) %>%
filter(terms != "intercept" , terms != "sigma") %>%
ggplot(aes(mean, terms, color = regions)) +
geom_vline(xintercept = 0, size = 1.5, lty = 2, color = "gray50") +
geom_errorbar(size = 2, alpha = 0.7,
aes(xmin = mean - 1.96 * std.error,
xmax = mean + 1.96 * std.error)) +
geom_point(size = 3) +
scale_x_continuous(labels = scales::dollar,
expand = expansion(mult = c(.1, .1))) +
scale_color_brewer(palette = "Dark2") +
labs(x="", y = "", color = "Region in Model?")+
theme_minimal()+
theme(legend.position="right",
panel.background = element_rect(fill = "#e5f5f9", color = NA))
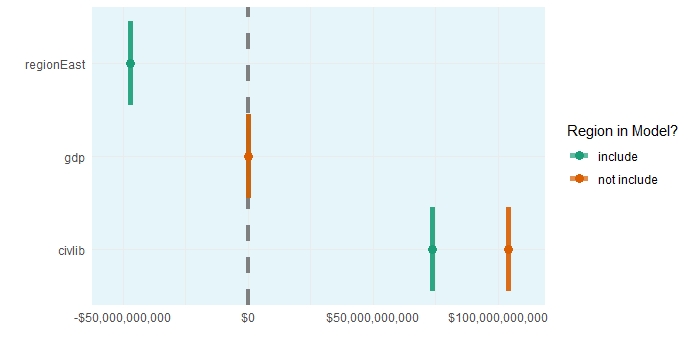
According to the plot above, while being in the east decrease the military expenditures, the effect of civil liberties increases the military budget, which is unexpected for me. This anomaly can be explained by the United States’ extreme values, which we have seen in the first plot we created before. Also, the prediction intervals seem to be near zero because of the MCMC simulation we did with the high iteration number.
References


Leave a comment